Eric ZhùinTowards Data SciencePlease Use Streaming Workload to Benchmark Vector DatabasesWhy static workload is insufficient and what I learned by comparing HNSWLIB and DiskANN using streaming workloadDec 1, 20231Dec 1, 20231
Eric ZhùinTowards Data ScienceFinding Needles in a Haystack — Search Indexes for Jaccard SimilarityFrom basic concepts to exact and approximate indexesAug 18, 20231Aug 18, 20231
Eric ZhùGPT-4’s Maze Navigation: A Deep Dive into ReAct Agent and LLM’s ThoughtsIn this post I dissect a GPT-4 ReAct Agent capable of navigating a maze, and reveal GPT-4’s thoughts and built-in skills.May 10, 20233May 10, 20233
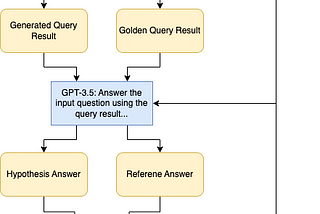
Eric ZhùHuman-Aligned Text-to-SQL EvaluationIn my last post about Text-to-SQL using GPT-3.5, I pointed out the issue with existing benchmark’s evaluation metric: it rejects perfectly…Mar 18, 20231Mar 18, 20231
Eric ZhùWhat is Coming Next for Text-to-SQLText-to-SQL is a natural language processing (NLP) task that involves converting natural language questions into SQL queries that can be…Mar 7, 2023Mar 7, 2023